
You can do whatever you want, as long as you don’t mess with my database!
Many companies, developers, and decision makers, including our customers, are trying to introduce microservice architecture in the future for digital transformation and IT transformation. These days, we have made every effort and spent a lot of money on building a Kubernetes container infrastructure, a more complex and larger-scale monitoring and management mechanism, drastically reforming the organization and development process, and even breaking down and re-training the software architecture for decades.
Software developers are even more painful. They have learned all kinds of new development processes and specifications, new development tools, and new architecture concepts. They have to learn and study various design patterns, agreements, and technical methods. They have to understand theories while also worrying about implementation issues. In terms of practical application and architecture implementation, one loses the other.
What is sad is that no matter how hard you try, there will always be more pitfalls and more difficult issues waiting in front. This road is trembling, not only unsure, but also drives all participants, especially the frontline developers in pain.
What are the key issues in introducing microservices? What makes everyone so painful? Failed in turning containers into microservices for a long time and leaving all microservice consultants at a loss?
“Data” issues that we don’t want to face
In fact, we all know that the most difficult problem lies in “data”, but we just simply are unwilling to do it, unwilling to decouple, because changing the structure and management of data means taking many risks. It is a huge bet for companies. The data decoupling is a heart surgery, and no one can easily do it.
Therefore, no matter how we talk about data decoupling, dismantling tables and dismantling databases, database per service, event sourcing or CQRS (separation of command and responsibility), it is just a matter of paper, no one really implements it well. All those common design patterns and technologies of these microservice architectures, often require a lot of input from developers. The various complex mechanisms and architectures are enough to make developers big heads. We can’t say who has the silver bullet, but we are sure that a wrong step may drive you on the wrong track with no way back.
However, the microservice architecture cannot be correctly implemented without dealing with data issues. The wrong implementation method will bring more performance issues, management issues, development complexity issues, and even worse than the old software architecture. This contradiction has caused everyone a headache. It is hard to deal with but no way avoided, it stucks!
You can do whatever you want, as long as you don’t mess with my database!
You should have been unable to listen to the various design patterns and theories of microservices. You have long been bored with supreme principles such as CQRS, Event Sourcing and Database per service, because in your eyes, this is almost impossible to achieve in the existing enterprise architecture. Touching your data is like killing you. More often than not, it may kill the entire technical team, even your boss!
On the premise of “Don’t mess my database casually!”, what are the methods or strategies? Everyone wants to know the answer.
Fortunately, in the past few years of experience in microservices consultants, we have indeed found a way to enable companies to meet most of the data mechanism requirements of microservice architecture without directly operating on the database. Especially for companies that are new to microservices, it is a painless and acceptable option.
The answer is to start with the “data caching and provisioning strategy” to implement a data cache and provision platform for microservices.
Data caching strategy for microservices
How to use the data caching strategy to meet the needs of the microservice architecture can be found in the history of the frontend. Today, when the front-end is independent or even micro-front-end, we no longer rely on a single or specific server and source to respond to different needs, different regions, different browsers, different devices, and even different bandwidth speeds. Instead, it relies on the CDN to deliver front-end data and content, and slices and provisions the content required by the front-end to suitable content providing servers according to the needs of the end sides. These servers are located even all over the world.
Let’s look back at the microservice architecture. Under the distributed architecture, a similar mechanism is actually needed to provision and cache data to the nearest database according to the needs of the target service. However, under the back-end microservice architecture, this provisioning and caching will be more complicated. In addition to supporting more data sources, database types, and different message queue systems, it also needs to be able to meet two-way and many-to-many provisioning and caching requirements.
For a more complete consideration, even the provisioning “Latency” level and “Throughput” must be considered to realize the architecture and technology of parallel distribution. If an optimized container platform integration can be achieved for fault tolerance, horizontal expansion and dynamic deployment, that will be the best strategy.
In addition, each cache pipeline also needs to be deployed more quickly and flexibly, and easier to manage.
The deployment and maintenance of the huge and multi-party data cache pipeline is the key

Decentralized cache and provision architecture of microservice data center
It can be said that the huge data cache pipeline or data provision pipeline can support the data supply required by microservices. With the agile development and online speed of microservices, the deployment efficiency and maintenance ease of these thousands of data pipelines should be the key to the formation of microservice architecture.
In addition, under the huge service interweaving of the microservice architecture, it is not easy to provision and cache data from multiple sources. If there is no overall design, when developing and designing the microservice architecture, just the unification of data format, synchronization frequency and communication protocol are enough to make developers from different services and applications quarrelsome. A little incident or data format modification and adjustment, even if the change is extremely small, will directly destroy other related services.
Therefore, how to deploy and maintain these data cache and provision pipelines has gone beyond the topic of the microservice architecture design model, and is also a management topic.
Proper provisioning mechanism can solve the issue of microservice data sharing

Data sharing issues of microservices
All cached data are created in accordance with the needs of the target business and service. In addition to provisioning only “necessary” data, it also means that the use of cached services can use the most labor-saving and fast way to obtain data. Moreover, because it has been independent of the original data source or database, any abnormalities or changes in the original data source will not be directly affected.
In addition, if a filter mechanism is introduced in the cache pipeline, it can even achieve de-identification, security scanning, etc., reducing the security problems of sensitive and important data, and it will be easier to mix with third-party systems and hybrid clouds without any doubts for integration in the future.
Microservices depend on the size and deployment efficiency of the cache pipeline
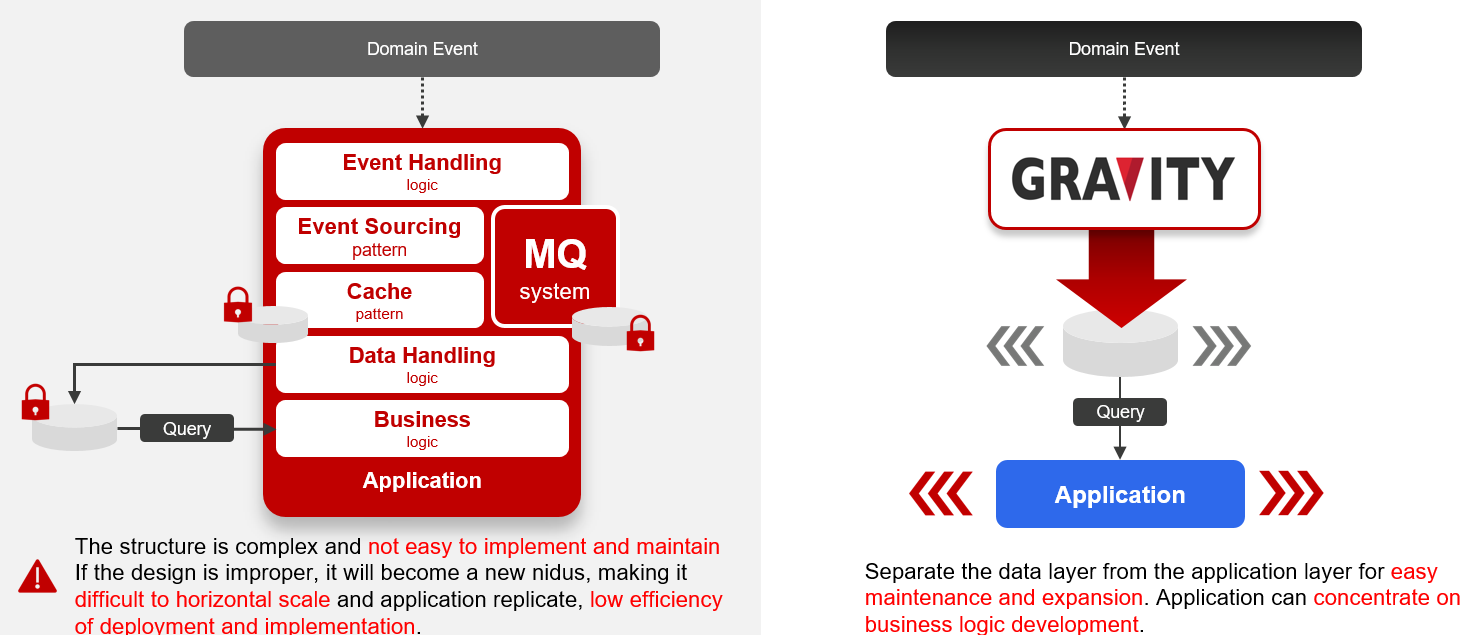
The Gravity solution provided by Brobridge can free application developers
It is not difficult to realize the data provision mechanism required by the microservice architecture. The difficulty is how many resources the average enterprise has to concentrate on this matter and turn it into a universal and easy-to-use component and architecture. Or let the technical staff who should be devoted to application development waste a lot of effort to take care of these complicated mechanisms that are not related.
To put it bluntly, these mechanisms are actually the Event Sourcing, CQRS, Message Queuing that are often heard in the microservice architecture, as well as the interface to the traditional event architecture (EDA, Event-Driven Architecture), and data event capture (CDC), data copying (Replication) and ETL often mentioned in big data. But integrated design is one thing. After integration, maintenance, deployment, and expansion are another thing, and its throughput and data synchronization performance are completely different fields.
Hard-working application developers spend a lot of time taking care of these requirements and mechanisms. Is there enough room to implement practical applications? The fundamental reason why many companies have been unable to truly implement the microservice architecture is that they spend too much time learning by practice, and every application and service has to learn again, which is quite painful.
Therefore, a microservice data cache and provision platform that can be deployed agilely is a necessary component of the microservice caching strategy.
Gravity, the data cache and provision platform you need

Agile deployment, microservice data cache and provision platform
Applications are changing rapidly, and the introduction of agile development aims to respond to changing business needs. Different businesses also require different data supplies. Only a cache pipeline that can be deployed agilely can keep up with the development of microservices. To achieve such an architecture, the Ambassador model must be adopted to implement a data cache platform.
To this end, we have been pondering for two years, during the consulting period, we found the pain points and needs from the customer’s bitterness and wailing, and invested in the realization of the Gravity solution, hoping to let the customer’s developers free from the hell of microservice data management.
Features are as follows:
● Deploy and use, no development
● Special parallel pipeline diversion technology, low latency and high throughput
● Multi-channel cache can be deployed agilely through YAML
● Scalable to support multiple event sources and MQ protocol (Kafka, NATS, RabbitMQ)
● Integration of external CDC data sources
● Simultaneously support heterogeneous database systems (MySQL/PostgreSQL/Oracle/MSSQL/MongoDB, etc.)
● Support event loss fault tolerance and data recovery
● Built-in event sourcing
● Built-in data snapshot
● Customizable event and data filtering rules
● Highly integrated with Kubernetes to support rapid horizontal expansion
More application scenarios derived from Gravity in the future
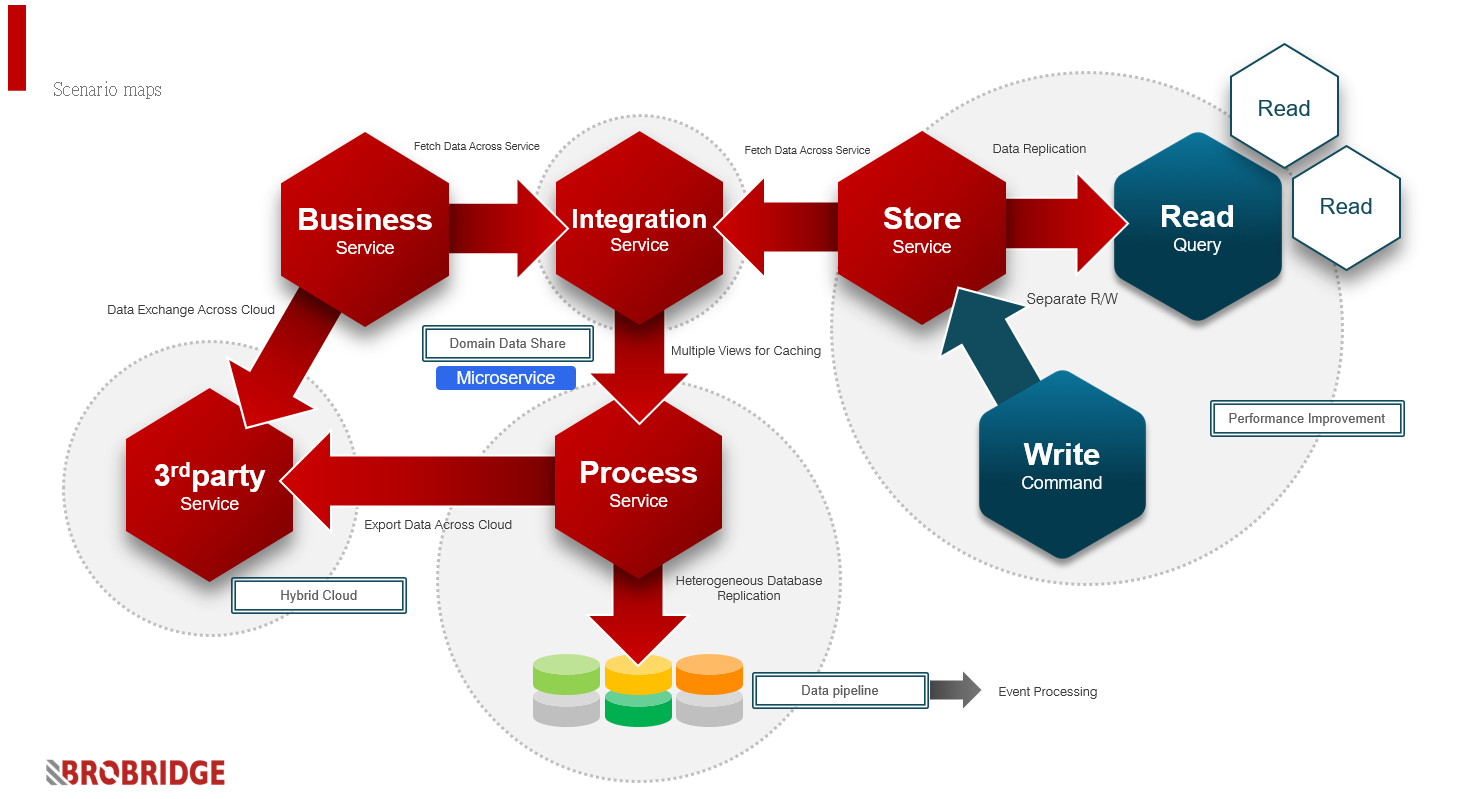
Behind the data cache and provision platform, there are more derivative scenarios
The data issue of microservice architecture is just the beginning after the introduction of data cache and provision platforms. After the issue of data sharing and throughput of microservices is resolved, there will be requirements for hybrid cloud and cross-third-party applications in the future. But don’t worry, as long as the cache data pipeline is sufficiently complete and easy to deploy and manage, this will not be a problem.
It will mess up, don’t confuse the transaction mechanism with data issues!
Finally, in past experience, if you want to use a set of methods to solve the transaction mechanism and data management issues at once, it usually does not end well. The complexity of the intertwining is far from the average developers can easily grasp. Many technical personnel’s questions and bottlenecks on the path of microservices are often due to the fact that they are not thinking through the “Grand Unified Theory” and are getting more and more biased, or making the entire architecture too complicated.
Therefore, the most ideal situation is “segment processing”. The data provisioning and caching mechanism are processed first, so that most microservice architectures can take shape and play a role in practical applications, and then face and handle the transaction mechanism problems. Regarding the issue of trading mechanism, we have the decentralized trading solution, Twist, which is another matter.
The source of information in this article is based on the practical experience of Brobridge, as well as the microservice architecture design training course and Gravity solution description. If you want to know more about the microservice architecture design and CQRS issues, you can contact us. If you want to import the “Data Cache Platform” to lay a solid foundation for your microservice introduction road and also prepare for the future “Data Center” and “Data Relay Platform,” you are welcomed to contact us.
To learn more about containerized infrastructure and cloud native technologies, consider joining us at KubeCon + CloudNativeCon NA Virtual, November 17-20.





