
Author: Goutham Rao, Individual Contributor, Portworx by Pure Storage
Bio: Goutham (Gou) Rao is a co-founder of Portworx and an individual contributor of the now CNBU, part of Pure Storage (PSTG). Previously, he was the CTO and executive director of data protection at Dell. Gou joined Dell through the acquisition of Ocarina Networks, where was the co-founder, CTO, and chief architect. Gou has a master’s degree in Computer Science, graduating with a 4.0 GPA from the University of Pennsylvania. Gou has been awarded over 45 patents.
We’ve all heard it since the inception of Kubernetes. “Data doesn’t belong here.” “Put my data in a declarative, dynamic infrastructure orchestrator? No way!” Do these statements ring true with you today? Or are you finding more and more that your developers and application architects are investigating why certain types of data being co-resident with your microservices and container-based applications is beneficial?
More and more enterprises are realizing the benefits of data residing in Kubernetes, and for good reason – they’re classifying their data and placing it where it is the most impactful to their business and applications.
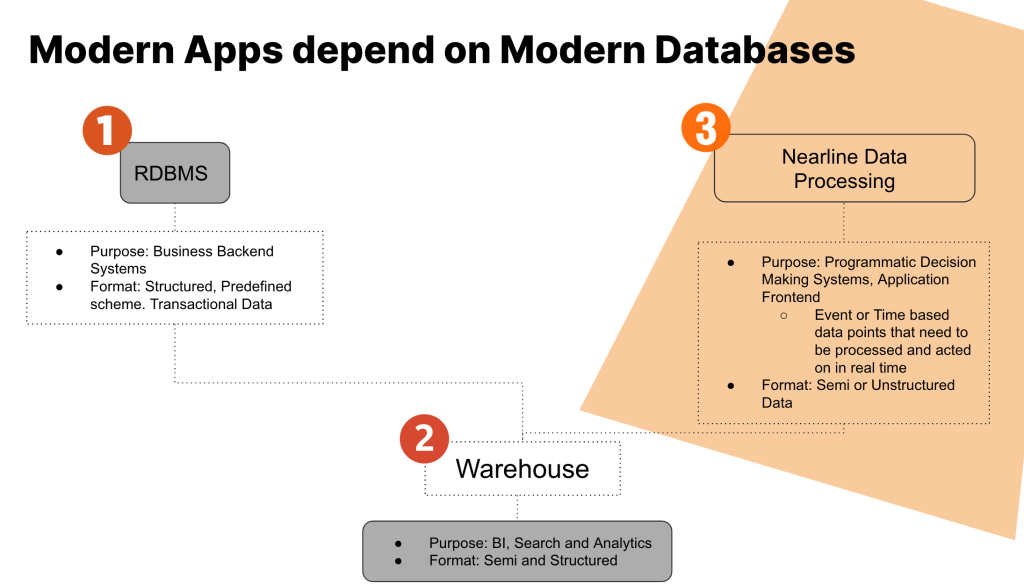
Data today can be classified into three primary categories:
- Business backend data (“the company jewels”)
- Data lakes and warehouses (“everything, everywhere, all at once”)
- Nearline data (“precise and surgical – how and where it’s needed”)
Let’s dig a little deeper into each of these, define what “data” means in each of these categories, and answer the question for each – “Does this data belong in Kubernetes?”
The Company Jewels
Let’s rewind our view of the industry for a couple of decades. Back then, a database meant Oracle, SQL Server, or other relational databases that needed highly-skilled DBAs, big iron servers connected to expensive and resilient networking infrastructure, and huge amounts of SAN storage that needed to be resilient to failure and highly available.
The data in these RDBMS were the fuel for almost every enterprise to power their core transactional enterprise applications for things like financial transactions, inventory management, or patient records. One characteristic of these databases were strict schemas that were well defined, thoroughly planned, and rarely updated – and when they did need to be updated, it could take months or even years of planning to make a change.
Just like the infrastructure required to support these critical data sets, these databases were the monoliths of the enterprise – indivisible, uniform, and the foundation of business processes that allowed the enterprise to be successful and profitable. Hardly seems like the type of data that would thrive in a declarative, high-churn environment like Kubernetes, right? You may not want to run your 100TB SQL Server database inside Kubernetes, but if you’ve got a small application that requires a RDBMS and you want data locality and the flexibility that Kubernetes orchestration provides, it might be a good fit.
Fast forward to today – no longer do we only have the old-school relational databases we grew up with. We now have data warehouses for analytics of near-time and historical transactional data, and data lakes that can hold huge amounts of information that can give us…
Everything, Everywhere, All at Once
HDFS. Hadoop. Yarn. ETL. Business Intelligence. Variable data types. Impossible amounts of incoming data. It’s madness – how can we create actionable, data driven processes to further our business outcomes and delight our customers based on all of this data?
You might recognize the title of this section from the award-winning best motion picture of the year. It’s one of my favorite films of all time – and ironically, the story and plot of this film can be a parallel to what businesses can achieve if they properly analyze the near-time and historical data they have collected. If you haven’t seen it yet, I highly recommend it – while you watch, think of how it relates to the amount and types of data your business ingests and how to use it to your advantage as you watch the main character move throughout the plot.
Whereas data warehouses historically have relatively well defined ingest and read schemas for data and are fairly structured, data lakes can essentially consume data in any format or type, lack a structured ingest schema, and only define schema on read. There is a fine line between a data lake and a data swamp – you can either gain great data driven insights, or you can drown and get stuck in a quagmire of information.
This type of data doesn’t quite fit the bill for running in Kubernetes – lakes are large, immovable objects, lacking the need for agile movement and deployment wherever they are needed. When you need water from a faucet in your home, does it come from a lake in your backyard? Or does it come from a remote lake or reservoir which is connected to water treatment facilities, delivered through a network of pipes and eventually ending up in your home? You need it delivered in a manner that is…
Precise and Surgical – How and Where It Is Needed
Modern applications today require modern databases and data services, such as unstructured NoSQL DBs like MongoDB, streaming services like Kafka, and analytic services such as Elasticsearch. These typically change in schema and size frequently since they directly reflect the data structures in the application code being developed.
But does a DBA sitting in a corporate office define these schemas and methods needed for data that is processed in near real-time? Almost never – the application developer, data scientist, or data engineer is typically responsible for understanding exactly what, how, and where data is needed when used with microservices and container-based application architectures.

When we look at the cloud native development tenets of distributed microservices, the leveraging of service oriented architectures, and agile development methodologies, it makes sense for application developers to have the capabilities to use the data they need how and where it is needed. Velocity is critical for today’s cloud native application developer to meet time to market requirements – this means data needs to be self-service oriented wherever possible, and the control plane for the databases or services being used must be accessible and known to the developer.
Creating and consuming data such as this inside Kubernetes simply makes sense when being consumed or generated by applications running on Kubernetes. Why make application developers learn the intricacies of deploying, securing, and running applications on a VM, or have another team of infrastructure specialists do it for them? Can they easily make their data portable from an Amazon RDS instance to an Azure SQL DB or Google Cloud SQL DB if the underlying cloud platform needs to change? Or should they just be able to deploy the database needed inside the respective EKS, AKS, or GKE cluster via one common method and manifest?
Can your developers deploy the database or service on their k3s or minikube install on their workstation or laptop for local development purposes, knowing that it will work seamlessly once it goes into production? Can they easily and dynamically scale the instances needed up or out depending on the needs of the consuming application code, or will they have to go through onerous and time-consuming processes for a DBA to provision, secure, and protect what they need? Can they easily guarantee resiliency and availability of the data needed regardless of running in a public cloud or on-premises?
There are a multitude of benefits to generating and consuming nearline data as close to your applications as possible – both at the development and infrastructure levels of your organization:
- Self-service deployment of databases and data services
- Data portability between diverse cloud platforms
- Common deployment and configuration methods across cloud platforms
- Local development consistency for application developers that matches production environments
- Simple scalability out or up when needed using Kubernetes orchestration methods
- Resiliency and availability of data using persistent volume replicas
Which leads to the fact that…
Data DOES Live In Kubernetes!
In today’s modern infrastructures that run modern applications, we don’t move lakes. We never mess with the company jewels. But there’s no reason we should treat nearline data like these other monolithic stores of data. Do you remember when all Amazon did was sell books online? Or when Netflix only sent you DVDs in the mail? How about when Google was just a simple search engine? The point of these questions is that a product, company, or technology starts as one thing – and when successful can grow into supporting different use cases, selling different products, or entering different markets altogether. Kubernetes is no different.
Persistent Volumes reached GA status back in 2019 with the Kubernetes 1.14 release. Fourteen releases later (at the time of this writing), new use cases are being explored and deployed into production, enterprise storage vendors have developed CSI drivers to support persistent data in Kubernetes, and entire companies and products have been created to provide cloud native storage services for Kubernetes. Database-as-a-Service (DBaaS) on Kubernetes is a reality for developer self-service and rapid provisioning. Communities such as Data on Kubernetes are thriving and have an entire day at each KubeCon to share best practices, use cases, and learn from each other!
While early Kubernetes purists may continue to state that “data doesn’t belong in Kubernetes” – I would argue that the industry, application developers and architects, platform engineers, and large multinational firms disagree and are currently reaping the benefits. You simply have to identify what “data” means to you, the types of databases and data services you require and how your applications generate and consume data on Kubernetes, and there’s likely a solution just waiting for you.
Join us at KubeCon + CloudNativeCon North America this November 6 – 9 in Chicago for more on Kubernetes and the cloud-native ecosystem.





