
Today more than ever, data is driving value creation for enterprises across the world. The data created at the edge of the edge close to where customer interactions take place is the primary source of this value, yet such data found at the ‘stateful edge’ does not age well. Real-time analysis and interference have become increasingly critical for operations, but this only serves to generate further processing at the edge sites.
At the same time, new use cases are evolving that are taking advantage of the data found at the edge, improving the customer experience, generating new revenue, and more efficiently responding to events that maximize the efficiency and quality of the products requiring this. Video analytics, image processing, Digital Twin, and location-aware services are just a few examples of types of applications where data is created and processed at the edge to generate significant value for enterprises.
Cloud Computing versus the ‘Stateful Edge’
Edge computing complements cloud computing as it brings cloud-like services close to where data is generated and required the most. For end-user devices that require a fast roundtrip response time, edge computing provides a number of benefits which can’t be matched by a purely cloud-based computing service.
| Cloud Computing | Edge Computing | |
| Time to insight | Network latency between data centers and devices takes time to process the data and provide timely insights. | Near real-time makes inference more valuable and eliminates slow response time |
| Cost | Moving a large amount of data transfer to Cloud data center incurs high data transfer costs. | Data is processed locally at the edge node, reducing backhaul costs. |
| Scalability | Scale up and scale out as needed. | Scale up or scale out might requires new hardware. |
| Manageability | Centralized management with CaaS and PaaS platform | Centralized management provided by multi-domain orchestrators |
Caption: Edge Computing offers significant benefits when compared to Cloud Computing
As more service providers turn towards 5G for their operations, a scalable, secure, cloud-native infrastructure is imperative in order to provide a service both the operators and customers can rely on. A standalone 5G core eliminates the hardware-centric, centralized architectures of the past and embraces a cloud-native distributed infrastructure perfect for building and operating networks. This approach uses microservices and runs on a service-based, containerized architecture enabling reliable service delivery, all the way to the far edge of the network. As a result, providers can create faster, optimized network performance to meet the customer’s expectations.
Edge solutions provide low latency and high bandwidth processing at the device level, as well as high performance data offload, trusted computing, and storage. In addition, they use less network bandwidth, due to the data being processed locally. Unlike cloud computing, where all the raw data is transferred to a centralized data center, only the aggregated results are uploaded to the cloud. Edge computing is also able to provide better data security, as only aggregated , depersonalized data moves, out of the local network.
A high-speed, private 5G network
5G connectivity enables faster, local, processing, enabling new use cases, including cutting-edge, low latency uses cases and applications capable of generating data rapidly from the edge. While edge computing can be deployed on networks other than 5G, such as 4G LTE, the opposite is not necessarily true. In other words, companies cannot truly experience the full benefits of 5G unless they leverage edge computing infrastructure.
As 5G networks continue to be rollout at an ever-growing rate, the relationship between edge computing and 5G wireless will continue to grow. However, companies will still be able to deploy edge computing infrastructure through a number of different connectivity models, such as wired and Wi-Fi, if necessary. However, with the higher speeds on offer from 5G, especially in rural areas that aren’t served by wireless networks, it’s more likely edge computing infrastructure will leverage a 5G network.
Data Management requirements for the ‘Stateful Edge’
The edge infrastructure has a unique set of requirements, including a low footprint and the requirements for a high degree of automation. Kubernetes-based, edge application delivery will foster standardization and efficiency. Still, there remains a need for a software-defined storage addition that can support the protection and management of valuable data at the edge with a high degree of automation.
Kubernetes can support a standard CSI interface where storage services can be added using the common standard. The storage layer needs to support a small footprint whilst providing a robust data persistency for stateful applications, which includes always-on availability with self-healing and advanced data placement.
Even though Kubernetes significantly aids automation, the addition of containerized microservices does add a level of complexity to the relationship of an application to its network and storage devices. Therefore, in terms of cloud native storage, just snapshotting and cloning storage volumes is no longer enough. In order to fully realize edge automation, one also needs to snapshot the other constructs such as application metadata, configuration, SLA policies, networking and etc. This will enable teams to very quickly rollback an entire application to a previous state or clone it so that one has a fully functional running database from a previously taken snapshot. The storage-only way of doing things goes against the agility and efficiency expected of a platform like Kubernetes and will hamstring your overall solution’s capabilities.
For the stateful applications running on a few nodes, storage and data management solutions for Kubernetes that can offer high performance are vital, especially for sequential ‘write’ and ‘random’ read workloads that run on hyper-converged infrastructure internal storage.Snapshots need to protect not only the persistent data volumes across multiple POD and notes but also the entire Kubernetes configuration at any point in time, including the stateful sets. Snapshots are thinly provisioned and based on re-directed on-WR technology and therefore do not consume any additional replicated data.
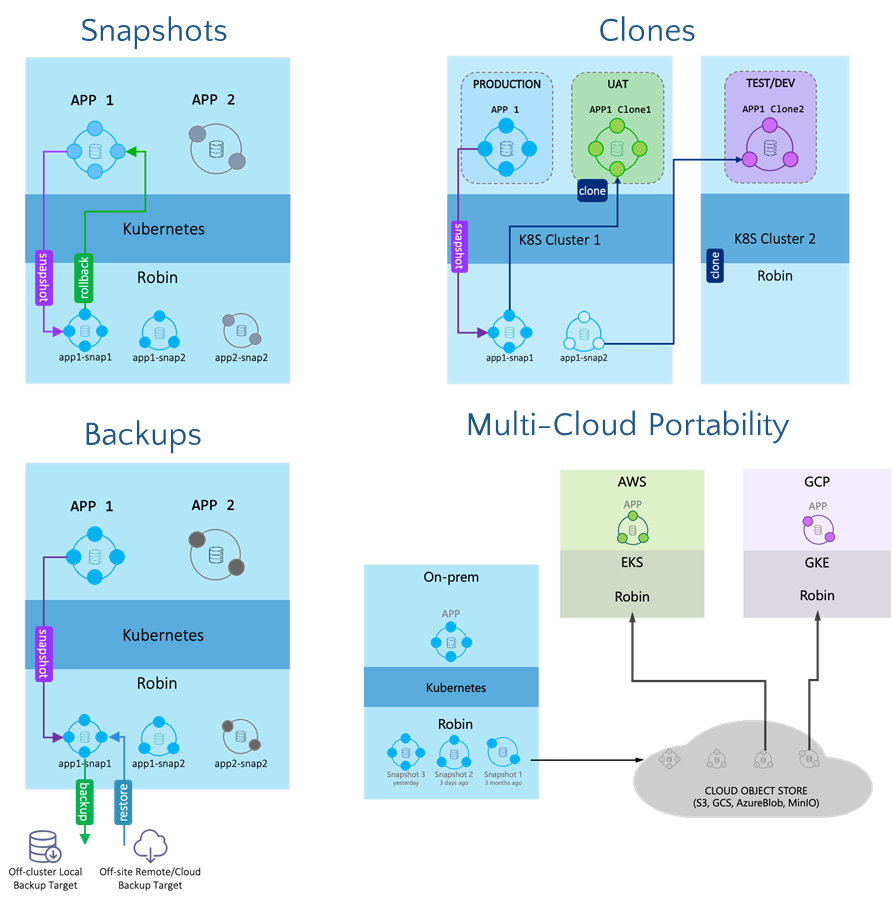
Caption: Kubernetes-based solutions include a comprehensive set of data services, including snapshots, clones, and backup.
The storage needs to be able to provide backup and clone capabilities, which can be very helpful for the in-place upgrade of stateful applications or for supporting the mobility of a workload back to the central data center or cloud.
Robin.io offers a standards-based, high-performance software platform that is software-defined and supports multiple Kubernetes distributions, making it a perfect solution for stateful edge deployments.
-By Mehran Hadipour, VP Global Business Development and Alliances, Robin Systems, A Rakuten Symphony Company





