
Resilient production systems are the dream of every organisation. Resiliency is complex, with many aspects to consider when thinking about what makes systems resilient, and monitoring alone cannot achieve resiliency. For instance, monitoring can let you know when something goes wrong, possibly in real time, but the incident happened regardless. True resiliency would mean recovering from incidents without noticeable effects on end-users.
Chaos engineering has changed the way to think of resilient production systems. With new native tools emerging for us to harness, we can introduce scenarios to test against our environments, such as Kubernetes clusters. These scenarios of various incidents, introduced individually or in groups, can be used to test out the resiliency of systems to see what actually happens in the face of such events. By using chaos engineering tools, you can see how powerful and resilient your systems are against such events.
Chaos engineering for Kubernetes simply means creating disruptions within your clusters, such as killing pods, spiking load in the cluster’s network, and the like. and testing them against such events so that any production failures can be predicted early. Such tests can be conducted in a scheduled manner, or as part of a regular continuous integration / continuous delivery (CI/CD) pipeline.
Chaos Experimenting is different from regular testing. Whereas a test validates a particular property against a claim based on existing knowledge, an experiment is conducted against a hypothesis. If the hypothesis stands, things are correct and if not, the mistake can be rectified and a further, refined experiment attempted.
From principlesofchaos.org, we have a four-step experimentation process:
- Start by defining ‘steady state’ as some measurable output of a system that indicates normal behaviour.
- Hypothesize that this steady state will continue in both the control group and the experimental group.
- Introduce variables that reflect real world events like servers that crash, hard drives that malfunction, network connections that are severed, etc.
- Try to disprove the hypothesis by looking for a difference in steady state between the control group and the experimental group.
Typically in Chaos engineering you tend to create an experiment or workflow that involves a hypothesis, such as “latency will not increase despite loss of n pods”, an experiment (deleting pods, slowing the traffic etc.), conducting the experiment, minimising the blast radius and then making the process continuous. Over the years, there have been many tools created for this practice which are now becoming mature enough to do chaos engineering in production that allow us to predict effects of failures before they actually happen at scale. Two of the popular tools that we will discuss today are:
- LitmusChaos
- ChaosMesh
If you want to try either of these tools, we have made them available as one-click installs on our managed Kubernetes service at civo.com. Get $250 free credit when you sign up, which is more than enough to test out these apps and get a feel for chaos engineering.
LITMUSCHAOS
LitmusChaos is a CNCF Sandbox Project. It is a framework to practice chaos engineering on Kubernetes clusters in a cloud-native way.
Below are some of the features of LitmusChaos 2.0
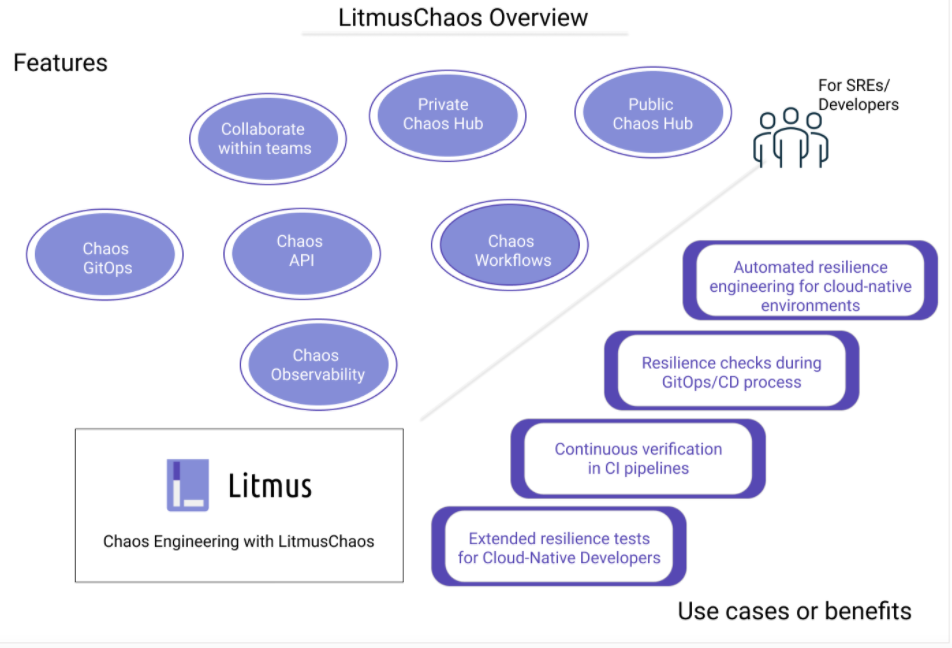
Benefits of LitmusChaos include:
- Team Collaboration, allowing for different levels (owner, viewer and editor) of access, and users can be created for different purposes.
- Chaos workflows can be chosen from a public chaos hub or created bespoke for organisations with a private chaos hub repository.
- GitOps integration: a powerful feature that allows you to connect to a git repository and store your workflows automatically versioned in git.
- New in Litmus 2.0, observability options that can help to visualize the exact chaos duration in tools like Grafana.
Architecture:
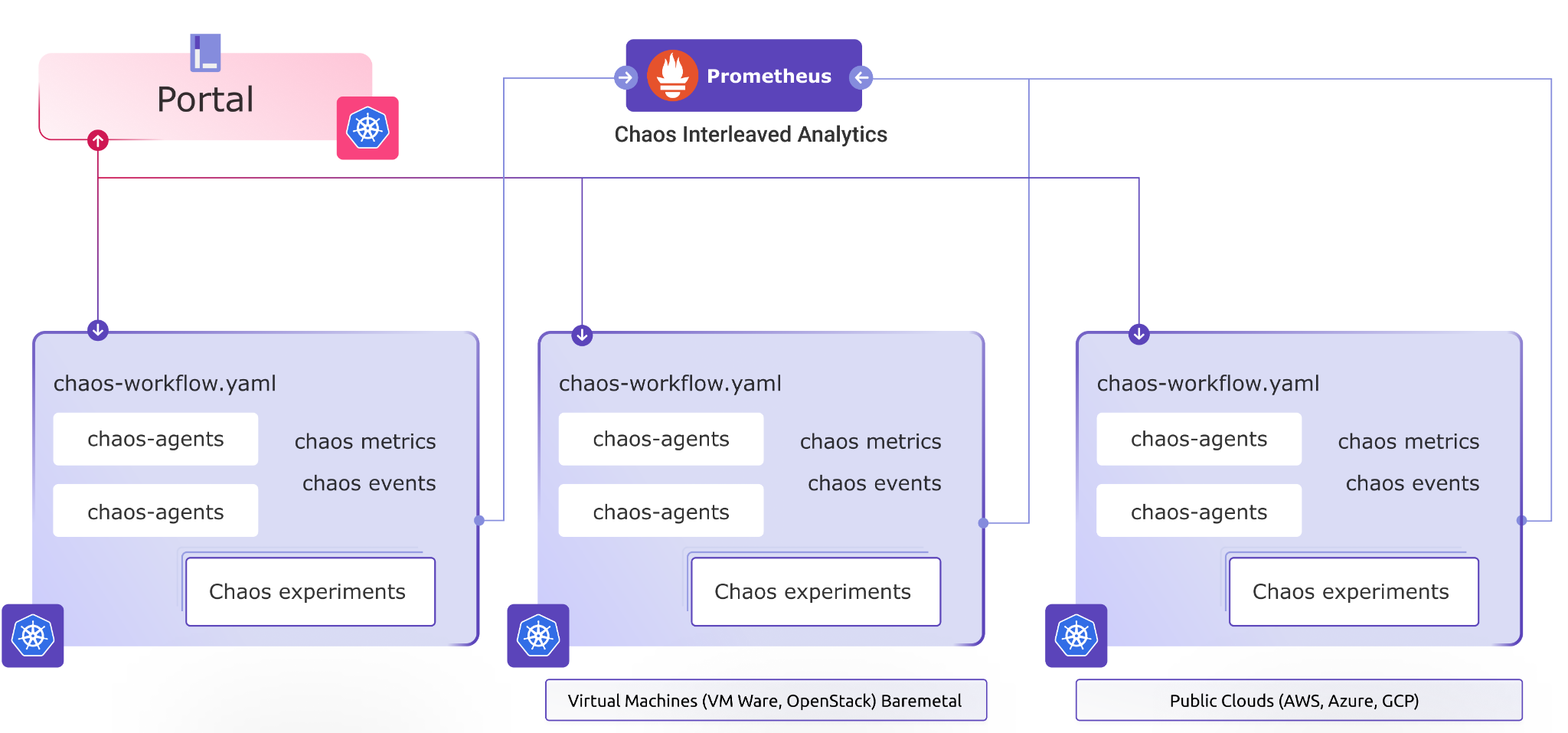
The two major parts in LitmusChaos are:
- Portal: Portal has three different components:
Web UI via which you can do everything including the creation of experiment workflows, selecting target clusters for running experiments on, enabling GitOps, and the like.
Litmus Server is there to handle requests from users and store data in the Litmus Database. It also acts as an interface to communicate between the requests and scheduling the workflow to the LItmusChaos Agent.
Litmus Database stores the workflows. However, if the GitOps option is enabled, these workflows are also stored in GitHub.
- Agent: Agent has the below components:
Chaos Operator watches for Chaos Engine CustomResources and then executes the Chaos experiment based on them
Custom Resource Definitions are installed onto the Kubernetes cluster, which include:
chaosexperiments.litmuschaos.io chaosengines.litmuschaos.io chaosresults.litmuschaos.io |
In the above example, the Chaos Experiment is applied from the Chaos Hub, the Chaos Engine links the experiment to the workload on the cluster, and the Chaos result stores the result of the experiment.
Chaos Probes are pluggable checks that can be defined within the ChaosEngine for any chaos experiment.
Chaos Exporter is there to export metrics to Prometheus.
Subscriber allows a workload to subscribe to a particular workflow.

Above are some of the chaos experiments that you can run in your Kubernetes cluster periodically to see how the cluster behaves with chaos and how you can tackle any potential failures in your application.
Chaos Mesh
Chaos Mesh is a chaos engineering platform for Kubernetes. Like LitmusChaos, it is a CNCF Sandbox Project. ChaosMesh can be used to create chaos events in your clusters such as killing pods, increasing network latency or system I/O. It has a dashboard for analytics and chaos events can be created via specific custom resource yaml files. Chaos Mesh is simple to use and can be installed on any Kubernetes cluster, whether on-premises or on a managed Kubernetes platform such as Civo..
Chaos Mesh has two major components:
- Chaos Operator : Core component for chaos orchestration.
- Chaos Dashboard: Web UI for managing, designing and monitoring Chaos Experiments
Architecture
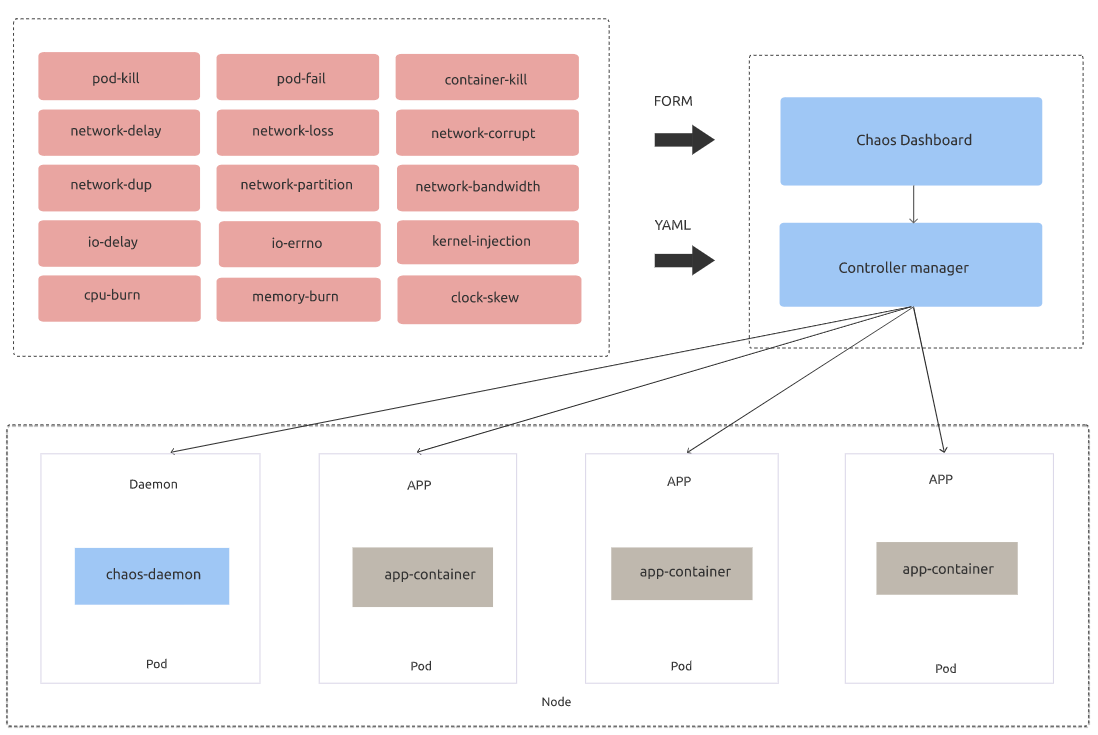
As you can see above, Chaos Mesh is installed in your cluster and you will have different CRD objects that Chaos Operator uses to define chaos objects. You can create the experiment from the list available on the Dashboard list and the Chaos daemon will run the actual experiment against your workload.
Currently-available custom resources that define experiments are:
- PodChaos
- NetworkChaos
- StressChaos
- TImeChaos
- IOChaos
- Kernel Chaos
- DNSChaos
As you can tell from the names, these cases cover most cluster functions to build a broad sense of resiliency.
Aside from the two tools detailed above, there are other chaos engineering tools on the CNCF Landscape. Much like the entire landscape, these tools are growing and evolving continuously, showing that the whole concept of Chaos Experimentation for production is becoming important for resilient production systems.
Check out our KubeCon talk where Karthik Gaekwad and I discuss chaos engineering and its importance, explore cloud-native tools for chaos engineering, and an end-to end demo showcasing a complete scenario.
Talk link – https://kccnceu2021.sched.com/event/08292428797f7ffea554d788dc8c9773
To hear more about cloud native topics, join the Cloud Native Computing Foundation and cloud native community at KubeCon+CloudNativeCon North America 2021 – October 11-15, 2021





