
In containerized environments, it can be complex to strike the perfect balance when it comes to excess capacity on your cloud-based Kubernetes infrastructure. Some margin is needed to handle spikes in demand, yet too much leads to increased operational cost.
In this quick post, we’ll share some highlights on balancing cost-efficiency and performance in containerized environments — including key considerations for different environments and workloads, as well as practical guidelines for optimization.
Key Considerations & Introduction
For the purposes of this post, we’ll consider excess capacity as defined by the aggregate amount of unused memory or CPU on your Kubernetes worker nodes. When determining how much excess capacity is appropriate, it’s important to consider:
Environment
In non-production environments, performance can take a backseat to cost efficiency. Non-production, test or R&D workloads typically tolerate higher variability in performance, offering prime opportunities for reducing excess capacity without impacting quality of services. In production environments, however, the balance shifts. There is a lower tolerance for disruption, making it essential to maintain a high level of robustness and reliability even when optimizing for costs.
Workload type
- Stateless workloads are highly elastic and can easily be scaled up or down with minimal impact. Excess capacity is less critical, but rightsizing ensures cost efficiency.
- Stateful workloads require data persistence and robust infrastructure. Here, performance and reliability are more important than immediate cost savings, and higher tolerance for excess capacity may be necessary.
- Batch/Data workloads often run on a schedule or in bulk. You can allocate excess capacity based on peak load expectations, but considerations like pod to node placement and workload schedule play a major factor in deciding how much excess capacity per node is appropriate.
- Data Persistence workloads should be carefully analyzed and have a stable buffer for excess capacity, given the need to maintain data integrity, with backup strategies and data storage costs as important considerations.
- AI/ML workloads often require intensive compute resources. Excess capacity is crucial for ensuring model training and inference processes run smoothly, but optimizing for cost while maintaining performance can deliver significant savings. These workloads are also often run in batches.
Basic Steps to Container Efficiency
Achieving container efficiency requires a systematic approach, starting from the smallest component and moving up. The basic steps include:
- Rightsize containers: Begin by optimizing container resource requests and limits to avoid over-allocating resources.
- Optimize pod placement: Design a strategy that places pods where they will have minimal resource contention, practices like affinity, anti-affinity, taints, tolerations, and selectors are often used to achieve an optimal outcome.
- Optimize node provisioning: Consider flexible auto-scaling solutions that adapt to workload needs, such as Karpenter.
- Optimize for price: Once container and pod efficiencies are in place, implement pricing strategies like Spot Instances and Savings Plans to further reduce costs.
Rightsizing Containers
One of the first areas to focus on when addressing excess capacity is the container level. Optimizing requests is key — by right-sizing containers (assigning just the right amount of CPU and memory without under or over-provisioning) you reduce wasted resources while still meeting workload needs.
The simplest approach for correctly sizing container requests is to analyze historical usage, focusing on metrics like average, p95, p98, p99 and maximum values to determine usage over a statistically significant amount of time.
Which thresholds are appropriate depend on the workload and its requirements. In some cases, we will want to use higher percentiles, while in others we have the flexibility to use lower. Here are some practical guidelines:
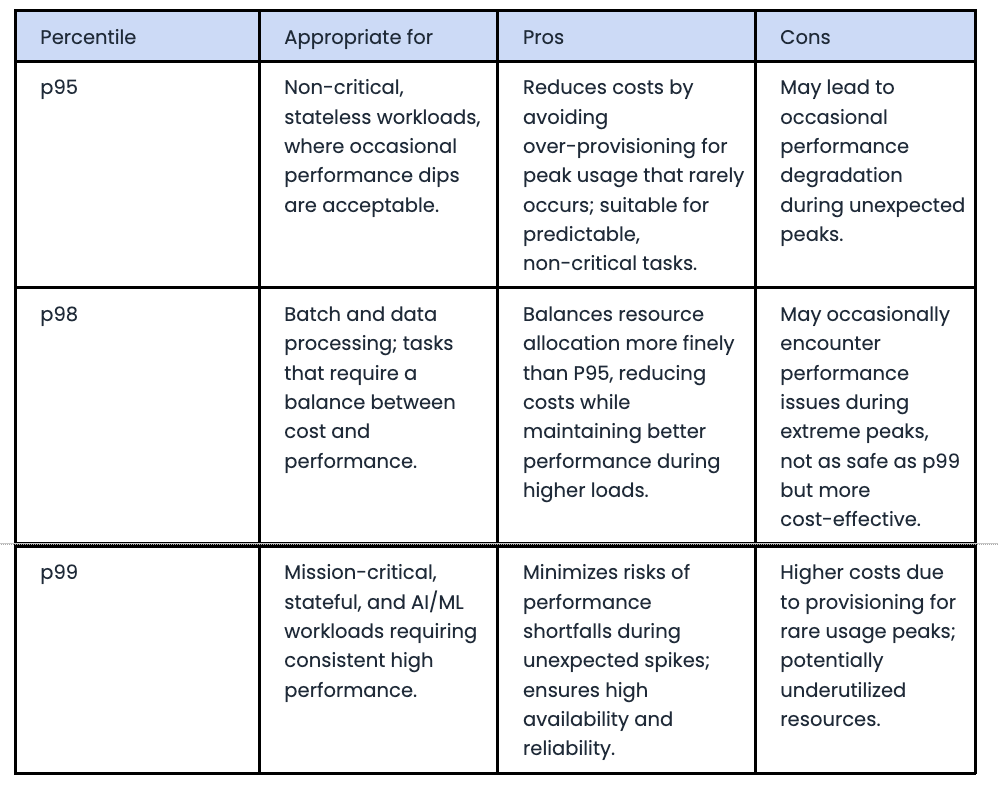
Infrastructure-level Efficiency
While optimizing requests at the container level is essential, it’s equally important to consider infrastructure-level strategies for efficient resource utilization. Key practical actions to take include:
Optimizing limits: While container requests are about resource allocation, setting appropriate limits at the infrastructure level ensures your cluster’s capacity isn’t overly constrained or wasted.
Pod placement: Intelligent pod placement, by leveraging placement strategies, can help partition workloads and reduce contention between them.
Isolating workloads: Splitting workloads based on their performance and capacity needs allows for better optimization of individual components of your infrastructure, helping avoid performance degradation in critical paths.
Consider the load pattern of workload execution: Ensure that your limits produce an appropriate amount of excess capacity based on anticipated bursts in resource requests.
Different workloads tolerate varying levels of excess capacity. Here are suggested guidelines:

The key takeaway is not to chase diminishing returns. Instead, focus on high-impact optimizations based on the workload type and priority.
Optimizing for price
There are two fundamental approaches to cost efficiency: use less, or pay less for what you use.
In an ideal scenario, we would always optimize container resources and infrastructure utilization before moving-on to price optimization tactics, but real-world environments are rarely so straightforward. Often, price is the first consideration, and organizations may not have the luxury of allocating resources to deep optimization exercises.
However, tools like Spot Instances, which provide access to spare capacity at up to 90% off, can offer short-term cost relief while giving you time to implement more strategic changes to capacity planning. Additionally, combining Spot Instances with long-term Savings Plans, which provide discounts for committed usage, can further reduce expenses and optimize resource allocation.
Balancing cost-efficiency and performance in containerized environments requires a strategic approach that considers both workload characteristics and infrastructure optimization while continuously monitoring success. By rightsizing containers, intelligently placing pods, optimizing node provisioning, and leveraging cost-saving pricing models, you can significantly reduce operational costs while maintaining performance.
For a more detailed and in-depth reflection on this topic, check out James Wilson’s session, “The State of Kubernetes Optimization and the Role of AI” at Kubecon 2024. Interested in learning more about nOps? Stop by our booth S25.
To learn more about Kubernetes and the cloud native ecosystem, join us at KubeCon + CloudNativeCon North America, in Salt Lake City, Utah, on November 12-15, 2024.





