
The cloud native stack brings numerous benefits to IT teams and organizations who use it, and Kubernetes is at the heart of the cloud native approach. At the same time Kubernetes itself is just a part of a puzzle. As soon as you have a reliable cloud native container orchestration platform in place, you must figure out how to deploy applications on top of the platform and determine how to manage the upgrades of these containerized applications, etc. Continuous integration and delivery tools help with this. In this article, we provide an overview of a canary deployment continuous delivery technique implementation on Kubernetes.
A canary deployment is a technique for introducing new versions of your applications into your environment to reduce the risk of large scale failure. Instead of replacing the old application, a new version of the application or service is introduced into your environment and a small subset of user requests is routed to that new version while monitoring the error rate. Once you are sure everything is ok, you can start to gradually increase the request flow to the new version and simultaneously decrease the flow to the old version until at some point you just turn the old version off. Should anything go wrong you can revert the process and work on the found issues.
Why do we need this approach if we could just use usual testing via the QA department? It’s important to note that the canary deployments technique does not replace the usual testing but allows you to limit probable harm caused by issues that may be revealed only during the production stage, even if everything worked fine in the testing environment.
Canary deployment in Kubernetes
What mechanisms in Kubernetes allow you to implement canary deployments? Among the main objects in a Kubernetes cluster that manage applications are PODs, deployments, and services. The deployment object is a high-level controller in Kubernetes that is intended to manage a given set of replicas of PODs of the same type. The deployment includes the definition of the POD template and uses this template to start new PODs.
Services in this picture are Kubernetes objects that provide traffic management and a single entry point for your application. When you deploy a service object, the object generates an intracluster internal IP address and sometimes an external endpoint too. Then any requests sent to this entry point are balanced between underlying PODs.
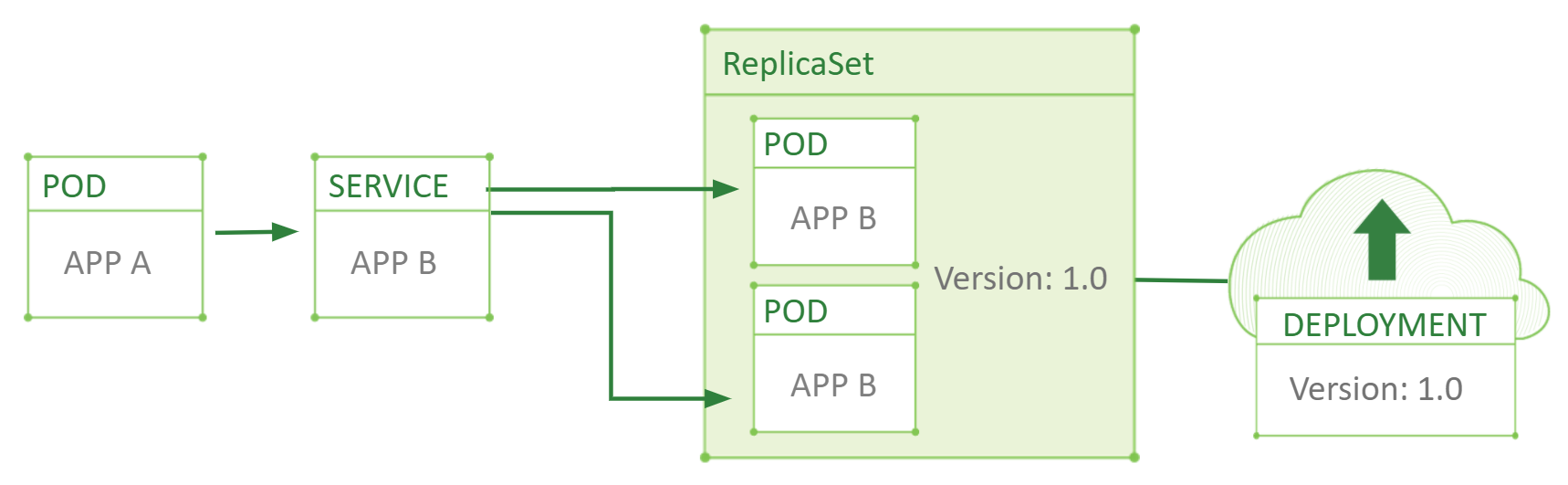
In the case presented in the graphic above, we start with the deployment running two PODs of version 1.0 and the service load balancing requests between those two PODs. When deploying a new version of the same POD in the canary deployments manner, you must create the new deployment object of a new version with a given number of PODs and POD labeling set so that the service will identify the new POD as the underlining one and start routing requests to this POD as well.
 Then you monitor your application to understand how many errors occur. If the error rate does not increase for the new version, you may start increasing the number of PODs in version 2 and simultaneously decrease the number of PODs in version 1.
Then you monitor your application to understand how many errors occur. If the error rate does not increase for the new version, you may start increasing the number of PODs in version 2 and simultaneously decrease the number of PODs in version 1.
Why can’t we just change the version within one deployment? The problem is that deployment is just a “one scenario to play” player. A single deployment cannot maintain multiple versions of the POD for a long time. Deployment is only intended to do a rolling update as fast as possible. If you change the existing deployment, it will start increasing the number of new PODs and decrease the number of old ones in an automated manner until all the PODs are replaced.
As soon as you transfer all your load to the new deployment, you can delete the old one and thus finalize the upgrade using only the Kubernetes capabilities.
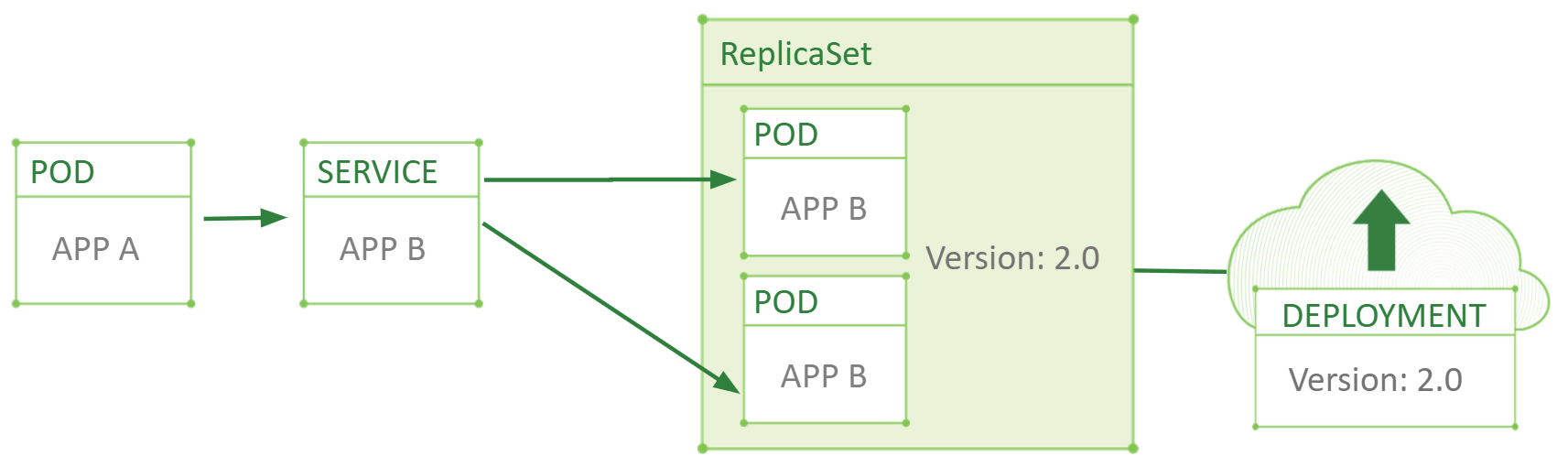
Is Kubernetes enough?
Unfortunately, there are a couple of problems with this approach. First of all, you have to manipulate multiple deployment objects so you must manually implement the logic of increasing the number of PODs in one of them, decreasing in another, and manually monitor the error rate.
Also, the traffic routing capabilities of services in Kubernetes are relatively limited, so you do not have much control over which POD the traffic is sent to and users may experience switching between old and new version responses. You cannot implement advanced strategies like rolling out a new version only to a certain subset of users, to do so would be a very complicated task.
Another problem is that traffic splitting depends on the granularity and the number of your PODs. If you run two to three PODs for your application, you cannot, as the first step of your canary deployment, route just 5% of your traffic to the new PODs — you will have to deploy a whole POD for the new version and with three old PODs the quarter of your traffic will go the new POD so it is quite a crude control.
Overcoming disadvantages — Service meshes
A service mesh — such as Istio — introduces a control layer over the inter-service traffic. While Kubernetes services work on the L4 level of the network stack, Istio and other service meshes work on L7, so they know the application protocols like HTTP and gRCP. They can view and analyze traffic, look into the request and response headers, intercept, adjust, and reroute the requests.
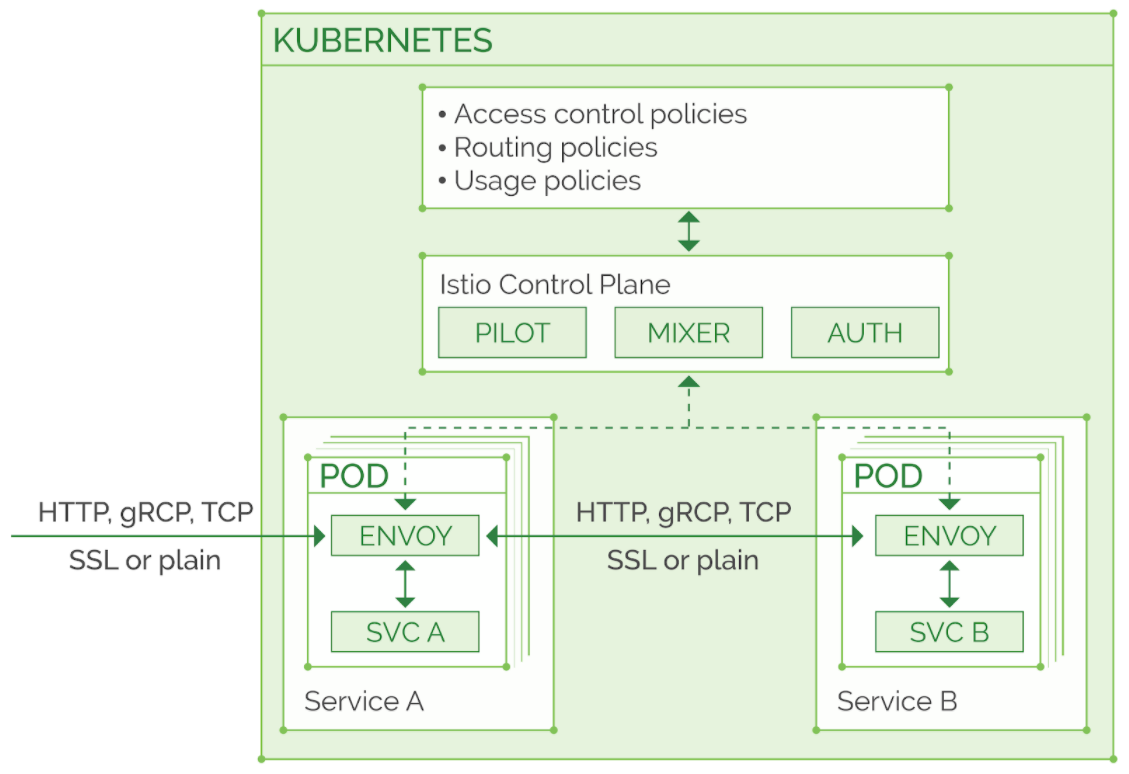
To do that, most meshes introduce sidecar proxies. In the graphic above, the ENVOY sidecar proxy is introduced into every POD of your microservices application and that service proxy processes all the service’s traffic, incoming and outgoing, according to the rules defined by the service mesh control plane.
Typically, service meshes also provide advanced monitoring and tracing capabilities. With a microservices architecture, simply monitoring the number of requests per service is not enough, you also want to see how requests from different user sessions propagate through your system and tracing tools like Zipkin and Jaeger are irreplaceable here.
As a result, a service mesh scenario, as presented in the graphic below, becomes possible.
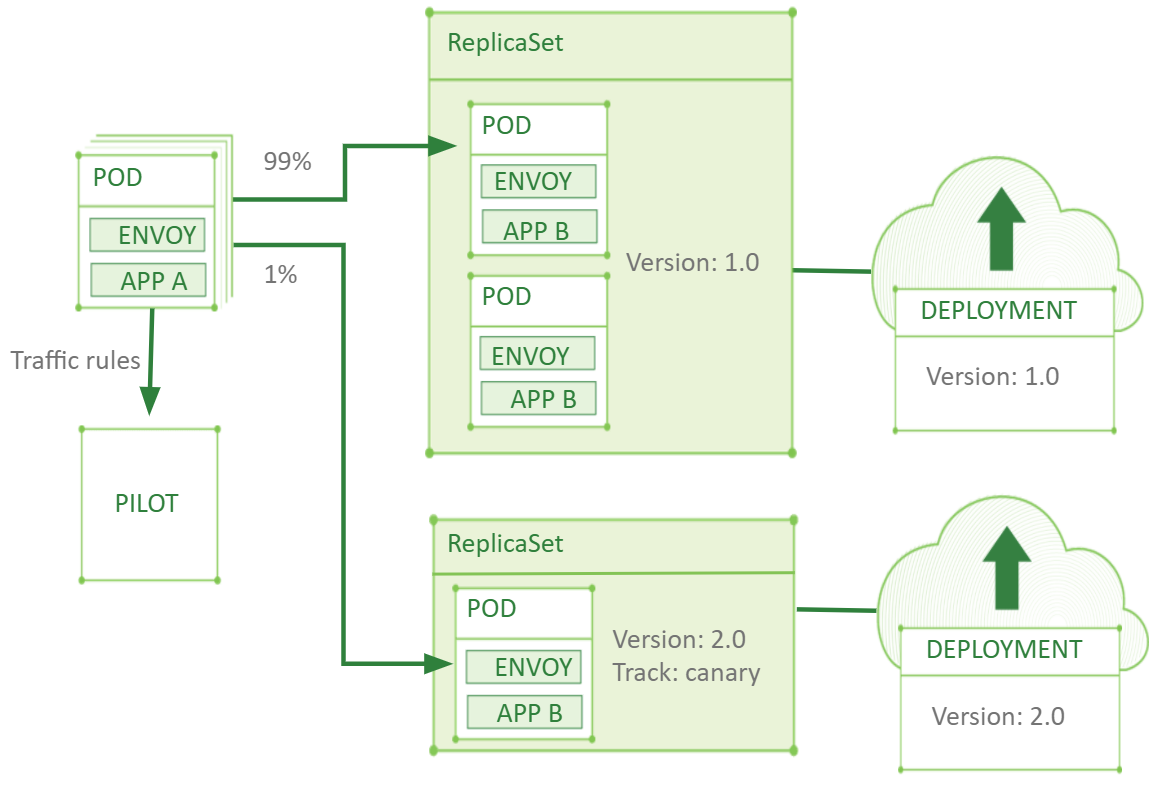
In this scenario, you have two PODs running version 1.0 of your application and one POD running version 2.0. With Istio you can create a virtual service which routes 99% of requests to the old version and 1% to the new version. Not only weights or percentage of requests can be set, but other conditions. For example, using the request headers that indicate the category of users you can only reroute requests of one specific category of users.
The share of rerouted requests will be exactly as specified and will not depend on the number of the PODs, so you can rely on the standard Kubernetes horizontal POD auto-scaling.
This way you can implement the approach we previously discussed when you gradually increase the number of requests going to the new version and then get rid of the old version. With Istio, you can also use strategies and patterns like a circuit breaker, error introduction, etc.
Where is Spinnaker in this picture?
While Istio provides a tool to shape and manage traffic, it does not provide you with tools to implement the canary release logic. Because every organization has different requirements for the successful deployment of applications, this logic should be customizable. Spinnaker is the tool to do exactly that — to create pipelines for the deployment including canary deployment cases. It also supports a number of target environments from private and public clouds to Kubernetes.

What does a continuous delivery process look like at a high level? Typically you have your continuous integration process which starts the pipeline and the flow. You start with your source repository (GitLab, GitHub, any other git repository), add in automated build pipelines (Jenkins, SaaS tools like CircleCI, and others), and a continuous delivery tool (Spinnaker in our case). Other essential elements of the process include the binary and image repository (e.g. Sonatype Nexus or a Docker Hub), and a monitoring tool (such as Prometheus, Influx, DataDog, Sysdig etc).
Jenkins watches your source code repository and each time you commit, it kicks off the pipeline which builds a Docker image and puts it into the Docker image registry.
Spinnaker watches the image registry for the new images, and as soon as a new image is built, it starts the pipeline to deploy the new version of an image into Kubernetes. A pipeline complexity can vary. You can automatically run tests in QA and, if all goes well, kick off the production canary deployment; it can include manual approval steps, conditional steps, etc. The whole process is often aided by the monitoring subsystem because Jenkins and Spinnaker need to receive feedback about the success of the canary deployment.
Beyond the basics
There are other considerations to bear in mind.
First, if you deploy an application you must take special measures to ensure your users do not experience any disruption due to interrupted in-flight requests. This can be achieved using reliable graceful shutdown in your application. Kubernetes provides a number of tools, such as readiness and liveness check, graceful termination timeout, etc. to achieve this.
On the topic of user experience, we should also mention the necessity of solid experience for the same user session. You probably want to avoid a situation where the same user switches between different user interfaces (old and new) within the same session, so we may need some routing rules sticking the deployment process to the session logic.
The next thing is that canary analysis strategies can be much more complicated than in our simple examples. When you deploy in real life, you must think about how Spinnaker can understand whether the new version is working or not. For example, if you rely on the actual load, consider what will happen if there are no user requests within the deployment period — how would Spinnaker assess the error rate in that case?
Also, managing stateful components is more complicated than stateless ones, which will make you think about the underlying data, etc.
Lastly, having many people working on your project you may be using the multi-branch development approach. As such, you may need to make your deployment and release strategies branch-related. This can be achieved but requires some additional configuration and organizational and technical support.
About us
Kublr is an enterprise-grade solution for managing Kubernetes clusters. Deployed on your infrastructure, Kublr delivers a “Kubernetes as a service”-like experience for IT operations, developers, and other teams. Kublr delivers comprehensive, flexible tools that ensure companies can deploy enterprise-class Kubernetes clusters from day one with support for multi-cluster, multi-cloud and hybrid environments.
To learn more about containerized infrastructure and cloud native technologies, consider joining us at KubeCon + CloudNativeCon NA Virtual, November 17-20.





