
Author: Gaurav Rishi
As containerized applications go through an accelerated pace of adoption, Day 2 services have become a here and now problem. These Day 2 services include data management functions such as backup and disaster recovery along with application mobility. In this new world of containerized cloud-native applications, microservices use multiple databases and storage technologies to store state and are typically deployed in multiple locations (regions, clouds, on-premises).
In this environment, what are the right constructs for designing and implementing these data management functions for cloud-native applications? How should you reason about the various data management options provided by storage vendors, data services vendors, and cloud vendors to decide the right approach for your environment and needs? This articles dives under the covers and address the pros and cons of various data management approaches across several attributes including consistency, storage requirements, and performance.
Defining a Vocabulary
Let’s start by deconstructing and simplifying a stack to show where the data may reside in a cloud-native application.
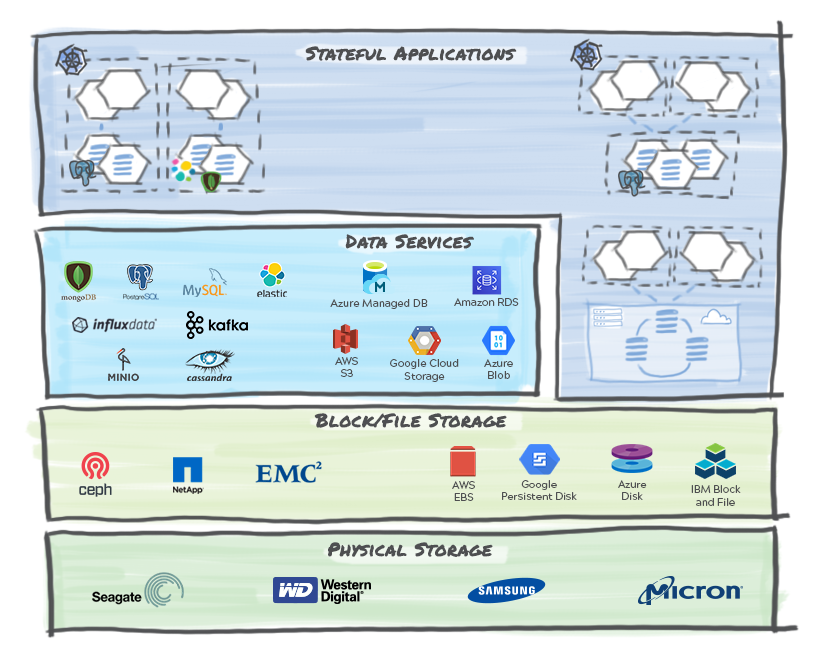
When thinking of data management, we could be operating on one (or more!) of the layers whether on-premises or a public cloud as shown in the figure above. Let’s enumerate these layers:
Physical Storage: This layer includes various storage hardware options that can store state in non-volatile memory with a choice of physical media ranging from NVMe and SSD devices to spinning disks and even tape. They come in different form factors including arrays and stand-alone rack servers.
File and Block Storage: This software layer provides File or Block level constructs to enable efficient read and write operations from the underlying physical storage. In both cases (file and block), the underlying storage could be stand-alone (local disks) or a shared networked resource (NAS or SAN).
Data Services: This layer provides various database implementations as well as an increasingly popular storage type, namely object (aka blob) storage. Applications typically interface with this layer and the choice of the underlying database implementations is based on the workloads and business logic. With microservices-based applications, polyglot persistence is a norm since every microservice picks the most appropriate data service for the job at hand.
Stateful Applications: The application layer is where the business logic resides and, in the cloud-native world, applications are implemented as distributed microservices. Almost all applications have state that needs to persist. While there are several patterns of storing application state, we need to persist and protect the following information in the context of a stateful Kubernetes application as an atomic unit:
- Application Data: Across various Data Services, Block, and File storage implementations spread across multiple containers.
- Application Definition and Configuration: Application image and the associated environment configuration spread across various Kubernetes objects including ConfigMaps, Secrets, etc.
- Other Configuration State: Including CI/CD pipeline state, release information and associated Helm deployment metadata.
An example of a stateful application is shown in the figure below which highlights some of the components and the associated state that needs to be protected. It is important to note that, for a real-word deployment, the application is composed of hundreds of these underlying components.
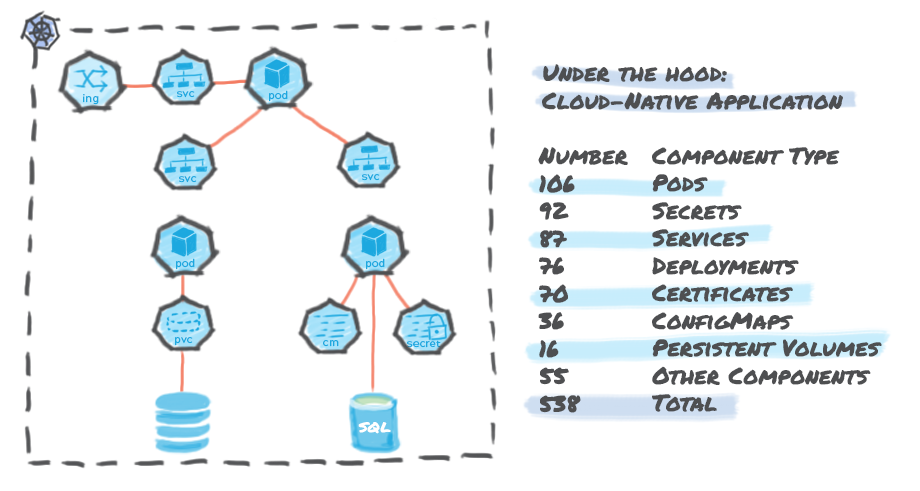
Flavors of Data Management
Now that we have built a vocabulary, let’s look at the various data management options to enable use cases like Backup and Restore, Application Mobility, and Disaster Recovery. We can categorize the data management approaches to protect data based on the layers we just explored. There are, of course, variations and one can also mix and match the approaches highlighted below. However, let’s enumerate the broad strokes approaches that will arm us with the additional vocabulary to then tackle the corresponding pros and cons.
1. Storage-Centric Snapshots:
In this approach, the snapshot capability provided by the underlying file/block storage implementation is exercised. This approach is transparent to the data service layer such as MySQL.
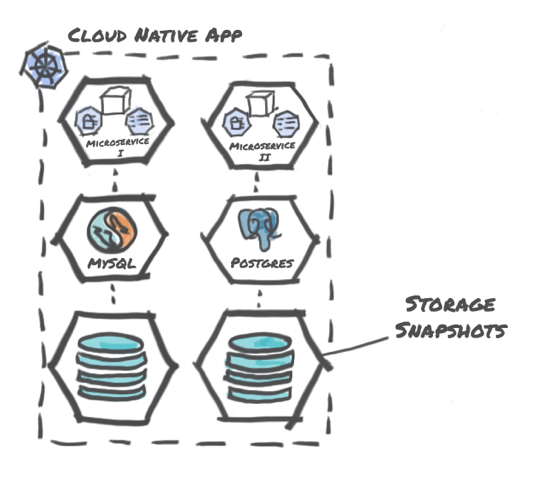 The result of this snapshot is often alluded to as being “crash-consistent” and the consistency achieved is similar to that when pulling the power plug. However, limitations include:
The result of this snapshot is often alluded to as being “crash-consistent” and the consistency achieved is similar to that when pulling the power plug. However, limitations include:
- Results are dependent on the underlying block/file implementation
- Might not be good enough when you need transaction-level granularity
- Need to restore the entire storage device vs. individual records or entries
- Limited failure domain, need to be mindful to avoid storage technology/vendor lock-in
2.Storage-Centric with Data Service Hooks:
In this approach, the data protection process like in the earlier method depends on the storage layer’s snapshot functionality. However, the data protection process makes a call into the data services layer to freeze and unfreeze the specific data service. Most data services support an API to allow these hooks to quiesce and un-quiesce the database in addition to flushing in-memory buffers.
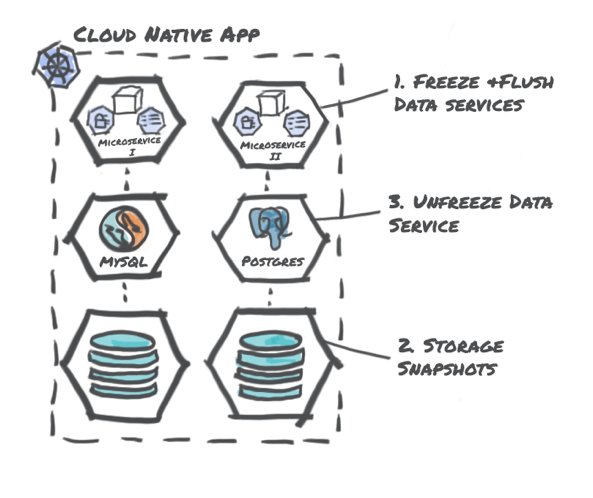
The primary advantage of this backup approach is that there is a better level of consistency while being quick. The disadvantages include:
- Data service is not available to the higher-level application during the time it is frozen
- Restoration process is not very granular
- Limited failure domain, need to be mindful to avoid storage technology lock-in
- Additional error-recovery code needed to ensure that the data service is never stuck in a frozen mode
3. Data Services Centric:
This approach involves a more top-down approach where the data protection system is not just aware of the data services layer but is tied and specific to the particular database implementation. There is a rich choice of tools and utilities available both in the open-source domain (e.g., pg_dump for PostgreSQL) as well as commercial offerings from various database vendors (e.g., Atlas Backup for MongoDB).
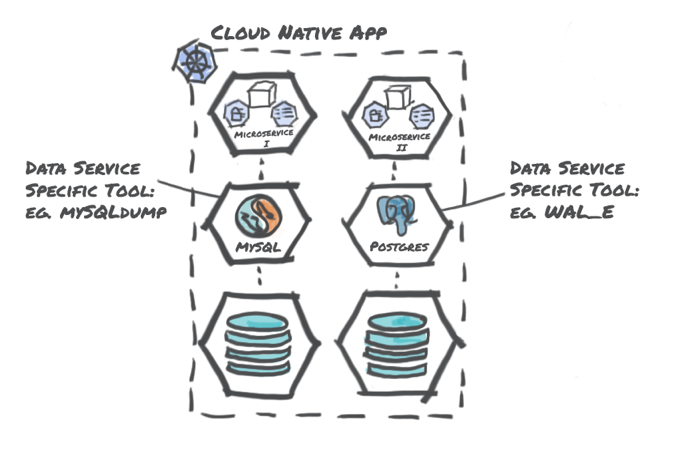
Advantages of this approach include:
- Potential storage space savings since database-specific compression techniques can be used such as only gathering incrementals since the last backup
- No dependency on the underlying file/block storage layer to support snapshotting capabilities, which is the case with locally attached storage in Kubernetes environments or ephemeral volumes in cloud environments such as NVMe
Disadvantages of this approach include:
- Does not abstract away the database
- An added access impact to the consumers of the data service while the protection process is in execution
- Recovery can take significantly longer than the other approaches highlighted above
4. Application-Centric
This approach is where things get interesting. Enterprises typically care about business continuity of an application, not the individual piece parts. As illustrated earlier, under the hood, a typical cloud-native application is composed of microservices with multiple data services, storage systems and related application components including Kubernetes objects.
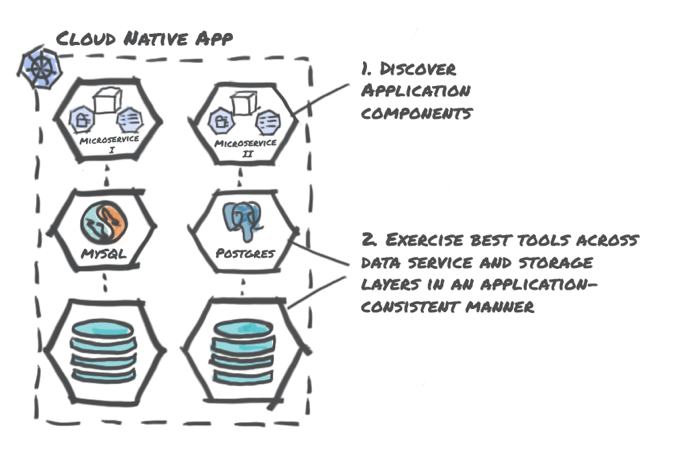
This microservices explosion coupled with a Kubernetes-based orchestration system that does not bind applications to specific nodes makes data protection for cloud-native applications very different from traditional server or hypervisor solutions. Consequently, enterprises in need of low recovery and restore times coupled with operational ease for these growing cloud-native applications need to take a fresh look at selecting a data management approach.
The advantages of this approach include a higher level of consistency and flexibility in working across multiple implementations of storage and data service vendors, giving enterprises the freedom of choice. An additional advantage includes the separation of concerns, whereby the IT/Operations team can independently set compliance policies on the application without requiring the developers to make code changes to enable data protection. Finally, this approach provides application mobility that can be extended across clusters, regions, and clouds.
The disadvantage of this approach is that this is a relatively new construct that has come into existence with the rise of cloud-native applications. However, with stateful Kubernetes applications becoming ubiquitous, this concern is fast disappearing.
Summary / TL;DR
We built on a vocabulary that deconstructed the definition of state in a cloud-native application to explore flavors of data management functions like backup and recovery and portability. Flavors of data management introduced here to protect application state included:
- Storage-centric snapshots provided by the underlying file or block storage,
- Storage-centric with data service hooks that spans across storage and data services layers,
- Data service-centric approaches that uses database specific utilities, and finally
- Application-centric that exercises all the above capabilities in a coordinated manner.
Each approach has its own pros and cons in terms of speed, consistency, and costs. The optimal approach will depend not only on the capabilities available but also on the specific application needs in terms of backup and recovery objectives and compliance needs. However, regardless of the approach, the unit of atomicity for a good data management solution needs to be application-centric (and not storage or data service specific).
Interested in learning more about zero-trust hybrid mesh architecture? Be sure to visit Decipher Technology Studios at KubeCon + CloudNativeCon San Diego to meet Jon and the rest of the Decipher team.
Gaurav Rishi is Head of Product at Kasten. He previously led strategy and product management for Cisco’s cloud media processing business. In addition to launching multiple products and growing them to >$100M in revenues, he was also instrumental in several M&A transactions. An engineer at heart, Gaurav is a computer science graduate and has an MBA from the Wharton School.





